Trong bài viết trước, chúng ta đã biết được các khái niệm quan trọng trong việc sao lưu và phục hồi dữ liệu oracle database. Cũng như các tính năng sao lưu phục hồi oracle mà oracle database hỗ trợ.
Và, sau khi hoàn thành bài viết này, bạn sẽ có khả năng:
- Cấu hình khu vực phục hồi nhanh (fast recovery area)
- Tạo nhiều bản sao của Control files (control file)
- Tạo nhiều bản sao của file redo log
- Cấu hình chế độ ARCHIVELOG
Bài viết này nhằm hướng dẫn bạn đạt được những mục tiêu cụ thể khi làm việc với hệ quản trị cơ sở dữ liệu Oracle. Bằng cách hoàn thành bài viết, bạn sẽ có kiến thức và kỹ năng cần thiết để cấu hình khu vực phục hồi nhanh, tạo bản sao của Control files và file redo log, cũng như cấu hình chế độ ARCHIVE LOG trong Oracle Database.
Việc cấu hình khu vực phục hồi nhanh (fast recovery area) là một phần quan trọng trong việc bảo vệ dữ liệu của hệ thống cơ sở dữ liệu. Khu vực phục hồi nhanh là nơi lưu trữ các bản sao và các file log phục hồi, giúp đảm bảo khả năng khôi phục dữ liệu sau khi xảy ra sự cố. Bằng cách cấu hình khu vực phục hồi nhanh, bạn sẽ tăng tính sẵn sàng và độ tin cậy của hệ thống cơ sở dữ liệu.
Việc tạo nhiều bản sao của Control files và file redo log cũng là một phần quan trọng trong việc đảm bảo tính sẵn sàng và độ tin cậy của cơ sở dữ liệu. Control files chứa thông tin quan trọng về cấu trúc cơ sở dữ liệu và là một thành phần không thể thiếu trong quá trình khôi phục dữ liệu.
Tương tự, file redo log ghi lại các thay đổi trong cơ sở dữ liệu và đảm bảo tính nhất quán của dữ liệu. Bằng cách tạo nhiều bản sao của Control files và file redo log, bạn sẽ tăng khả năng khôi phục và bảo vệ dữ liệu trong trường hợp xảy ra sự cố.
Cuối cùng, việc cấu hình chế độ ARCHIVELOG là quan trọng để có khả năng phục hồi cơ sở dữ liệu đầy đủ. Khi chế độ ARCHIVELOG được kích hoạt, các bản sao của các file redo log được tạo ra và lưu trữ trong khu vực được chỉ định.
Điều này cho phép bạn phục hồi cơ sở dữ liệu đến một thời điểm cụ thể trong quá khứ, cung cấp khả năng khôi phục linh hoạt và bảo vệ dữ liệu trước sự cố.
Bảo vệ dữ liệu: Các bước cần thiết để đảm bảo an toàn cho dữ liệu của bạn
Để đảm bảo bảo vệ tốt nhất cho dữ liệu của bạn, bạn cần thực hiện các nhiệm vụ sau:
- Lên lịch sao lưu định kỳ: Hãy đặt lịch để sao lưu dữ liệu thường xuyên. Khi xảy ra sự cố, bạn có thể khôi phục các file bị mất hoặc hỏng từ bản sao lưu này.
- Tạo nhiều bản sao của Control files: Control files chứa thông tin quan trọng về cơ sở dữ liệu. Để tránh mất mát dữ liệu, hãy tạo ít nhất hai bản sao của Control files để phòng trường hợp mất tất cả các Control files.
- Tạo nhiều nhóm redo log: Redo log được sử dụng để phục hồi dữ liệu sau sự cố hệ thống hoặc phương tiện lưu trữ. Để đảm bảo an toàn dữ liệu, hãy tạo ít nhất hai bản sao của mỗi nhóm redo log và lưu chúng trên các bộ điều khiển ổ đĩa khác nhau.
- Lưu trữ bản sao lưu của redo log: Khi mất file và phục hồi từ bản sao lưu, cần áp dụng thông tin redo để đưa dữ liệu lên đến điểm cuối cùng đã được commit. Để đảm bảo tính nhất quán của dữ liệu, hãy cấu hình cơ sở dữ liệu để lưu trữ thông tin redo trong các bản sao lưu của redo log.
- Cấu hình chế độ ARCHIVELOG: Đặt cơ sở dữ liệu trong chế độ ARCHIVELOG để đảm bảo rằng thông tin redo không bị ghi đè sau khi đã được ghi vào các data file.
Để thực hiện các nhiệm vụ cấu hình này, bạn có thể sử dụng công cụ quản lý Enterprise Manager Cloud Control hoặc dòng lệnh SQL.
Cấu hình Fast Recovery Area trước khi tiến hành cấu hình Archive Log trong Oracle Database
Cấu hình khu vực phục hồi nhanh:
- Được khuyến nghị để quản lý việc lưu trữ bản sao dễ dàng hơn
- Lưu trữ không gian (riêng biệt với các file cơ sở dữ liệu làm việc)
- Vị trí lưu được chỉ định bởi tham số DB_RECOVERY_FILE_DEST
- Kích thước được chỉ định bởi tham số DB_RECOVERY_FILE_DEST_SIZE
- Kích thước phải đủ lớn để chứa bản sao lưu, các bản ghi lưu trữ (archive logs), bản ghi lưu trạng thái trở về (flashback logs), các Control files được tạo thành bản sao và các nhóm redo log được tạo thành bản sao
- Được quản lý tự động theo chính sách giữ lại dữ liệu của bạn
- Cấu hình khu vực phục hồi nhanh bao gồm xác định vị trí, kích thước và chính sách giữ lại.
Ví dụ: Giả sử bạn đang cấu hình khu vực phục hồi nhanh cho cơ sở dữ liệu Oracle của mình. Bạn muốn đặt vị trí của khu vực phục hồi nhanh là “/u01/fast_recovery_area” và kích thước của nó là 100 GB.
Bạn có thể đặt giá trị của tham số DB_RECOVERY_FILE_DEST thành “/u01/fast_recovery_area” và giá trị của tham số DB_RECOVERY_FILE_DEST_SIZE thành “100G”.
Khi bạn thực hiện các thao tác sao lưu, lưu trữ bản ghi lưu trữ, tạo bản sao lưu của các Control files và nhóm redo log, hệ thống Oracle Database sẽ tự động quản lý và giám sát khu vực phục hồi nhanh dựa trên chính sách giữ lại được cấu hình.
Alter system set DB_RECOVERY_FILE_DEST_SIZE = 100G; Alter system set DB_RECOVERY_FILE_DEST = '/u01/fast_recovery_area ';
Khu vực phục hồi nhanh là không gian được dành riêng trên đĩa để chứa các bản sao lưu, các bản ghi lưu trữ (archive logs), bản ghi lưu trạng thái trở về (flashback logs), các Control files được tạo thành bản sao và các nhóm redo log được tạo thành bản sao.
Khu vực phục hồi nhanh giúp đơn giản hóa quản lý lưu trữ bản sao và được khuyến nghị mạnh mẽ.
Bạn nên đặt khu vực phục hồi nhanh trên không gian lưu trữ khác với vị trí của các file data cơ sở dữ liệu và các file log trực tuyến chính (primary online log files) và Control files. Số lượng không gian đĩa để phân bổ cho khu vực phục hồi nhanh phụ thuộc vào kích thước và mức độ hoạt động của cơ sở dữ liệu.
Nói chung, khu vực phục hồi nhanh càng lớn, càng hữu ích. Lý tưởng nhất, khu vực phục hồi nhanh nên đủ lớn để chứa bản sao của dữ liệu và Control files, cùng với các bản ghi lưu trạng thái trở về, bản ghi redo trực tuyến và các bản ghi lưu trữ cần thiết để phục hồi cơ sở dữ liệu dựa trên chính sách giữ lại.
(Nói ngắn gọn, khu vực phục hồi nhanh nên có ít nhất gấp đôi kích thước của cơ sở dữ liệu để chứa một bản sao lưu và một số bản ghi lưu trữ.) Quản lý không gian trong khu vực phục hồi nhanh được điều chỉnh bởi một chính sách giữ lại bản sao.
Chính sách này xác định khi nào các file trở nên lỗi thời, nghĩa là chúng không còn cần thiết để đáp ứng mục tiêu phục hồi dữ liệu của bạn. Máy chủ Oracle Database tự động quản lý không gian này bằng cách xóa các file không còn cần thiết.
Đảm bảo sẵn có Control files: Tối thiểu hai bản sao – Multiplexing control files

Một Control files (control file) là một file nhị phân nhỏ mô tả cấu trúc của cơ sở dữ liệu. Nó phải sẵn có để ghi bởi máy chủ Oracle khi cơ sở dữ liệu được gắn kết (mounted) hoặc mở. Nếu thiếu file này, cơ sở dữ liệu không thể được gắn kết và cần phục hồi hoặc tạo lại Control files.
Cơ sở dữ liệu của bạn nên có ít nhất hai Control files trên các thiết bị lưu trữ khác nhau để giảm thiểu tác động khi mất một Control files. Mất một Control files đơn lẻ làm cho trạng thái gặp sự cố của instance vì tất cả các Control files phải luôn có sẵn.
Tuy nhiên, việc phục hồi có thể chỉ đơn giản là sao chép một trong các Control files khác. Mất tất cả các Control files khá khó khăn để phục hồi nhưng thường không gây thiệt hại nghiêm trọng.
Nếu bạn sử dụng ASM làm kỹ thuật lưu trữ của bạn, chỉ cần có hai Control files, một trong mỗi nhóm đĩa (như +DATA và +FRA), thì bạn không cần phải nhân bản thêm.
Trong một cơ sở dữ liệu sử dụng Oracle Managed Files (OMF) – chẳng hạn như cơ sở dữ liệu sử dụng lưu trữ ASM – tất cả các Control files bổ sung phải được tạo ra làm phần của quá trình phục hồi bằng RMAN (hoặc thông qua Enterprise Manager).
Trong một cơ sở dữ liệu sử dụng lưu trữ hệ thống file thông thường, việc thêm một Control files là một hoạt động thủ công:
1. Sửa file SPFILE bằng lệnh sau, chỉ định đúng đường dẫn của các file của bạn:
ALTER SYSTEM SET control_files = '/u01/app/oracle/oradata/orcl/control01.ctl' , '/u02/app/oracle/oradata/orcl/control02.ctl' , '/u03/app/oracle/oradata/orcl/control03.ctl' SCOPE=SPFILE;
2. Tắt instance cơ sở dữ liệu.
3. Sử dụng lệnh của hệ điều hành để sao chép một Control files hiện có vào vị trí bạn chọn cho file mới của bạn.
4. Mở cơ sở dữ liệu.
(Xem thêm trạng thái khởi động của Oracle Database)
Redo log files

Các nhóm redo log được tạo thành từ một hoặc nhiều file redo log. Mỗi file log trong một nhóm là một bản sao của các file khác. Oracle khuyến nghị rằng mỗi nhóm redo log nên có ít nhất hai file trong một nhóm.
Nếu sử dụng lưu trữ hệ thống file, thì mỗi thành viên nên được phân phối trên các đĩa hoặc bộ điều khiển riêng biệt để không có sự cố hỏng thiết bị đơn lẻ nào ảnh hưởng đến cả nhóm log. Nếu bạn đang sử dụng lưu trữ dạng ASM, thì mỗi thành viên nên nằm trong một nhóm đĩa riêng biệt, chẳng hạn như +DATA và +FRA.
Việc mất toàn bộ một nhóm redo log hiện tại là một trong những sự cố hỏng thiết bị nghiêm trọng nhất vì nó có thể dẫn đến mất dữ liệu. Việc mất một thành viên duy nhất trong một nhóm redo log có nhiều thành viên là không đáng kể và không ảnh hưởng đến hoạt động cơ sở dữ liệu (ngoại trừ việc gây ra thông báo trong bản ghi cảnh báo).
Hãy nhớ rằng việc phân bổ đa luồng cho redo log có thể ảnh hưởng nghiêm trọng đến hiệu suất cơ sở dữ liệu vì một giao dịch không thể hoàn thành cho đến khi thông tin giao dịch được ghi vào các log. Bạn nên đặt các file redo log trên các đĩa nhanh nhất được phục vụ bởi các bộ điều khiển nhanh nhất của bạn.
Nếu có thể, không đặt bất kỳ file cơ sở dữ liệu nào khác trên cùng các đĩa với file redo log (trừ khi bạn đang sử dụng ASM). Vì chỉ có một nhóm được ghi vào một thời điểm nhất định, không có ảnh hưởng đến hiệu suất khi có thành viên từ nhiều nhóm trên cùng một đĩa.
Tạo nhiều bản sao redo log

Bạn có thể tạo đa bản sao cho redo log bằng cách thêm một thành viên vào một nhóm redo log hiện có. Để thêm một thành viên vào một nhóm redo log (với cơ sở dữ liệu đang mở và không ảnh hưởng đến hiệu suất người dùng), thực hiện các bước sau trong Enterprise Manager Database Express:
1. Chọn Storage > Redo Log Groups.
2. Chọn một nhóm và nhấp vào Add Member.
3. Trang Add Member hiển thị.
4. Đối với lưu trữ hệ thống file, nhập tên file và thư mục file. Nhấp OK. Lặp lại các bước này cho mỗi nhóm hiện có mà bạn muốn tạo đa bản sao.
Ngoài ra, bạn cũng có thể sử dụng cú pháp SQL để thêm một thành viên redo log vào nhóm redo log 1 (sử dụng ASM) như bên dưới:
ALTER DATABASE ADD LOGFILE MEMBER '+DATA' TO GROUP 1;
Khi bạn thêm thành viên redo log vào một nhóm, trạng thái của thành viên được đánh dấu là INVALID (như có thể thấy trong chế độ xem V$LOGFILE). Đây là trạng thái dự kiến vì thành viên mới của nhóm chưa được ghi. Khi một chuyển đổi log xảy ra và nhóm chứa thành viên mới trở thành CURRENT, trạng thái của thành viên thay đổi thành null.
Tạo Archived Redo log files – Archive Log trong Oracle Database

Máy chủ Oracle Database xem các nhóm redo log trực tuyến như một vòng tròn “đệm” trong đó lưu trữ thông tin giao dịch, điền vào một nhóm và sau đó chuyển sang nhóm tiếp theo. Sau khi tất cả các nhóm đã được ghi, máy chủ Oracle Database sẽ bắt đầu ghi đè thông tin trong nhóm log đầu tiên.
Để cấu hình cơ sở dữ liệu của bạn cho khả năng khôi phục tối đa, bạn phải chỉ dẫn máy chủ Oracle Database tạo một bản sao của nhóm redo log trực tuyến trước khi cho phép ghi đè lên nó. Những bản sao này được gọi là file redo log đã lưu.
Để tạo điều kiện thuận lợi cho việc tạo file redo log đã lưu bạn cần:
1. Xác định một quy ước đặt tên cho các file redo log đã lưu của bạn.
2. Xác định một hoặc nhiều vị trí để lưu trữ các file redo log đã lưu của bạn.
3. Đặt cơ sở dữ liệu vào chế độ ARCHIVELOG.
Lưu ý: Bước 1 và 2 không cần thiết nếu bạn đang sử dụng khu vực phục hồi nhanh (fast recovery area). Đích đến (destination) nên tồn tại trước khi đặt cơ sở dữ liệu vào chế độ ARCHIVELOG. Khi chỉ định một thư mục làm đích đến, phải có một dấu gạch chéo ở cuối tên thư mục.
Archiver (ARCn) Process trong Oracle database

ARC (Archiver) là một quy trình tùy chọn. Tuy nhiên, nó rất quan trọng trong việc khôi phục cơ sở dữ liệu sau khi mất một ổ đĩa. Khi một nhóm redo log trực tuyến bị đầy, máy chủ Oracle Database bắt đầu ghi vào nhóm redo log trực tuyến tiếp theo.
Quá trình chuyển đổi từ một nhóm redo log trực tuyến sang nhóm khác được gọi là log switch. Quá trình ARCn khởi tạo việc lưu trữ của nhóm log đầy tại mỗi log switch. Nó tự động lưu trữ nhóm redo log trực tuyến trước khi nhóm log có thể được sử dụng lại để đảm bảo tất cả các thay đổi được thực hiện trên cơ sở dữ liệu được bảo tồn.
Điều này cho phép khôi phục cơ sở dữ liệu đến thời điểm xãy ra lỗi ngay cả khi một ổ đĩa bị hỏng. Một trong những quyết định quan trọng mà người quản trị cơ sở dữ liệu (DBA) phải đưa ra là xem liệu cấu hình cơ sở dữ liệu hoạt động ở chế độ ARCHIVELOG hay chế độ NOARCHIVELOG.
– Trong chế độ NOARCHIVELOG, các file redo log trực tuyến được ghi đè mỗi khi có log switch.
– Trong chế độ ARCHIVELOG, các nhóm không hoạt động của các file redo log trực tuyến đã đầy phải được lưu trữ trước khi có thể sử dụng lại.
Lưu ý:
– Chế độ ARCHIVELOG là cần thiết cho hầu hết các chiến lược sao lưu.
– Nếu đích đến lưu trữ file redo log đã lưu tràn đầy hoặc không thể ghi, cơ sở dữ liệu sẽ dừng lại cuối cùng. Hãy xóa các file redo log đã lưu từ thư mục của file redo log đã lưu.
Archived Redo Log Files: Naming and Destnations
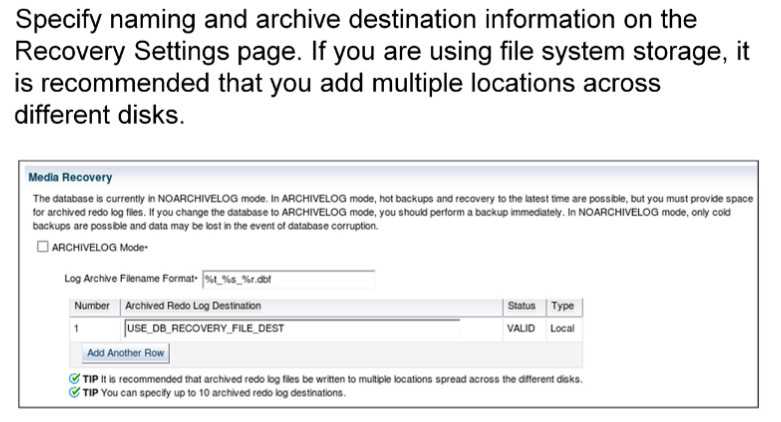
Để cấu hình tên và địa điểm lưu trữ các file redo log đã lưu thông qua Enterprise Manager Cloud Control, chọn Availability > Backup & Recovery > Recovery Settings.
Mỗi file redo log đã lưu phải có một tên duy nhất để tránh ghi đè lên các file log cũ hơn. Chỉ định định dạng tên như được hiển thị trên màn hình. Để giúp tạo ra các tên file duy nhất, Oracle Database cho phép sử dụng một số ký tự đại diện trong định dạng tên:
– %s: Bao gồm số thứ tự log như một phần của tên file.
– %t: Bao gồm số luồng (thread) như một phần của tên file.
– %r: Bao gồm ID resetlogs để đảm bảo rằng tên file log đã lưu vẫn duy nhất (ngay cả sau một số kỹ thuật khôi phục nâng cao có đặt lại số thứ tự log).
– %d: Bao gồm ID cơ sở dữ liệu như một phần của tên file.
Định dạng nên bao gồm %s, %t và %r làm tiêu chuẩn tốt nhất (%d cũng có thể được bao gồm nếu nhiều cơ sở dữ liệu chia sẻ cùng đích đến lưu trữ file redo log đã lưu).
Mặc định, nếu khu vực phục hồi nhanh (fast recovery area) được kích hoạt, USE_DB_RECOVERY_FILE_DEST sẽ được chỉ định làm đích đến lưu trữ các file redo log đã lưu.
Các file redo log đã lưu có thể được ghi vào tới 10 đích đến khác nhau. Các đích đến có thể là folder local (thư mục) hoặc từ xa (một bí danh Oracle Net cho cơ sở dữ liệu standby).
Nhấp vào Add Another Row để thêm các đích đến khác. Để thay đổi các thiết lập khôi phục, bạn phải kết nối với vai trò SYSDBA, SYSOPER hoặc SYSBACKUP.
Lưu ý: Nếu bạn không muốn gửi các file lưu trữ đến địa điểm này, hãy xóa USE_DB_RECOVERY_FILE_DEST.
Cấu hình Archive Log trong Oracle Database
Đặt cơ sở dữ liệu vào chế độ ARCHIVELOG để ngăn chặn việc ghi đè lên redo log cho đến khi chúng đã được lưu trữ.
Chúng ta có thể sử dụng lệnh SQL để đặt cơ sở dữ liệu vào chế độ ARCHIVELOG, cơ sở dữ liệu phải ở chế độ MOUNT. Nếu cơ sở dữ liệu hiện đang mở, bạn phải tắt nó, sau đó tiến hành theo các bước sau sau:
shutdown immediate startup mount alter database archivelog; alter database open;
Với cơ sở dữ liệu ở chế độ NOARCHIVELOG (mặc định), khả năng khôi phục chỉ có thể tiếp tục đến thời điểm sao lưu cuối cùng. Tất cả các giao dịch được thực hiện sau sao lưu đó sẽ bị mất.
Trong chế độ ARCHIVELOG, khả năng khôi phục có thể tiếp tục đến thời điểm thực hiện giao dịch cuối cùng. Hầu hết các cơ sở dữ liệu sản xuất được vận hành trong chế độ ARCHIVELOG.
